들어가기에 앞서,
Server Side Rendering을 지원하던 기존 Multi Page Form 방식에서 모바일 사용자가 증가함에 따라 React, Angular, Vue 등 Client Side Rendering이 가능한 SPA가 등장하게 되었다. SPA는 1개의 페이지에서 수정되는 부분만 리렌더링하는 등 여러 동작이 이루어진다. 그렇다면 SSR과 CSR의 차이는 무엇일까?
SSR

서버에서 렌더링 작업을 수행하는 SSR은 사용자가 웹페이지에 접근할 때 서버에서 페이지에 대한 요청을 보내고, 서버에서 html, view 등의 리소스가 어떻게 보여질 지 해석되어 렌더링 후 사용자에게 반환하는 방식으로, 전체적인 프로세스는 다음과 같다.

여기서 첫번째 단계는 다음과 같이 이루어진다.
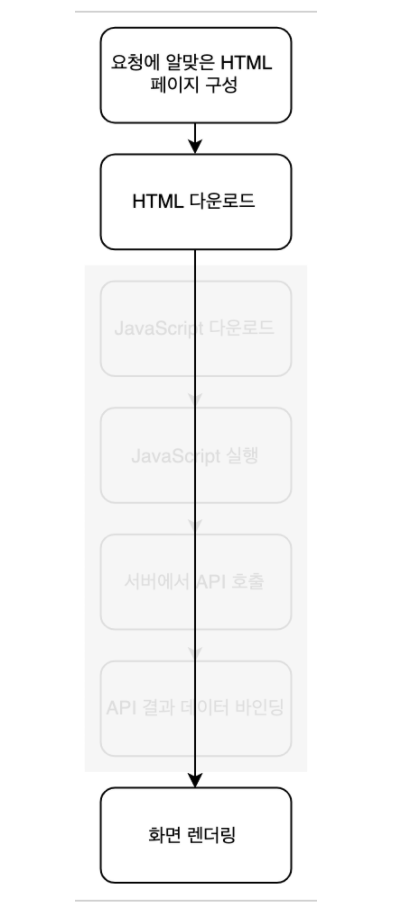
SSR이어도 Ajax 기능을 위해 클라이언트 렌더링 요소가 포함될 수 밖에 없다.
쉽게 설명하면, 페이지를 구성해서 그에 해당하는 html을 다운받아 화면에 렌더링하는 것으로, CSR에 비해 다운 받는 파일이 많지 않아 초기 로딩 속도가 빠르고, 사용자가 빨리 콘텐츠를 볼 수 있다. 근데 이 과정이 브라우저 👉 프론트 서버 👉 백엔드 서버 👉 데이터 베이스 를 거쳐 데이터를 받고 역순으로 브라우저까지 데이터를 가져와 그려야 하기 때문에, 페이지 이동/ 클릭 등으로 다른 요청이 생길 때마다 이 과정을 반복하면 변경되지 않은 부분도 계속해서 리렌더링되는 문제점이 있다. (서버 부하 등의 문제를 일으킬 수 있음)
CSR

CSR은 최초 1번만 서버에서 전체 페이지를 렌더링하여 보내주면, 이후에는 사용자의 요청이 올 때마다 리소스를 서버에서 제공받아 클라이언트가 해석하고 렌더링하는 방식이다. 전체적인 프로세스는 다음과 같다.


SSR에 클라이언트 렌더링 요소가 포함된다면, CSR는 SSR 없이 일관된 코드를 작성할 수 있다. (물론 아닌 경우도 있음)
즉, 먼저 데이터를 제외하고 화면을 그리는 코드들만 프론트 서버에서 다운받아진다. 이는 js 파일에 한번에 묶이기 때문에 첫 다운에 시간이 오래 걸린다. 따라서 초기 구동 속도가 SSR에 비해 느려지는데, 이는 code splitting 으로 해결할 수 있다. 하지만 아직 데이터를 다운 받은 상태가 아니다. 클라이언트의 요청이 발생하면 필요한 데이터만 백엔드 서버에 요청하여 받아온 후 해당 부분을 갱신하는 방식으로 SPA가 작동하기 때문에 서버 부하가 덜하다.
이와 관련된 문제는 검색 엔진 최적화에 취약할 수 있다는 점이다.
초기에 데이터 없이 html이 다운되기 때문에 검색봇이 해당페이지를 빈 페이지로 착각하여 Search Engine Optimization에 취약할 수 있다.
그래서 차이점은?
등의 차이가 있다.
CSR은 사용자의 요청에 맞게 필요한 부분만 다시 읽기 때문에 서버에서 전체 페이지를 다시 읽는 것보다 빠른 반응 속도를 기대할 수 있다. 하지만 초기 로딩 시
- html 다운: 페이지를 읽고
- js 다운: js를 읽고
- js을 실행하고
등등을 모두 마무리해야 사용자에게 콘텐츠가 보이기 때문에 화면을 렌더링하기까지의 초기 로딩 속도가 느리다. 하지만 그 이후에는 빠른 반응을 보인다.
SSR은 서버에서 view를 렌더링하여 가져오기 때문에, 초기 로딩 속도 (초기 화면 렌더링 속도) 가 빠르다.
Next.js란?
그래서 Next는 어떤 SSR과 CSR의 단점을 보완하는 걸까?
SSR은 불필요한 부분까지 리렌더링 되어 서버 부하가 발생할 수 있다는 점, CSR은 초기 로딩 속도가 느리고 SEO에 취약하다는 단점이 있다.
Next.js를 사용하여 첫페이지는 백엔드 서버에서 렌더링하여 빈 html이 아닌 데이터가 채워진 html을 받는다면 SEO 문제를 해결할 수 있다. 이후에는 CSR 방식에 따라 필요한 데이터만 받아 갱신한다면 서버 부하도 줄일 수 있다.
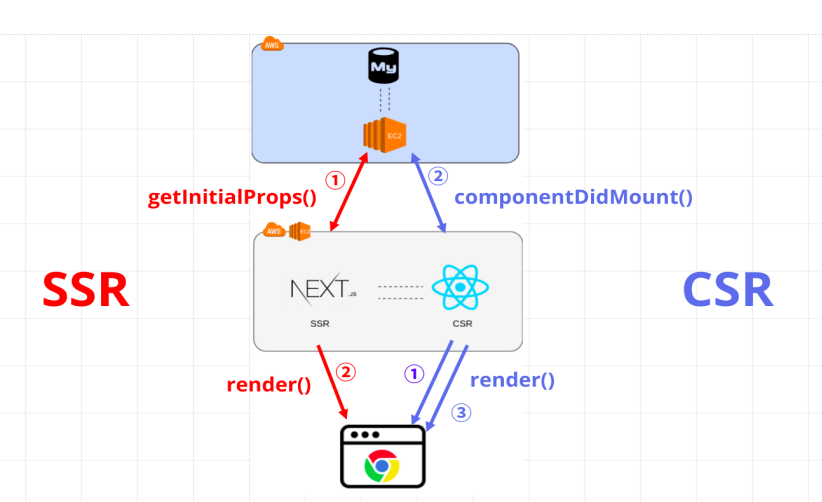
Next.js를 통해…
기존의 문제점인
- webpack과 같은 번들러를 통해 code를 번들하고 Babel과 같은 컴파일러로 변환해야 함
- code splitting과 같은 성능 최적화가 필요함
- 성능과 SEO를 위해 몇몇 페이지를 pre-render 해야할 수 있음
- React app과 데이터 스토어를 연동하기 위해 SSR 코드를 작성해야 할 수 있음
- 그냥, SSR과 CSR를 모두 사용하고 싶음
을 해결할 수 있다.
그러니까 Next.js의 특징은
- 페이지 기반의 라우팅 시스템 (CRA 시
page folder 생성)
- 한 페이지 당 SSG와 SSR을 지원해 pre-rendering 가능
- 자동화된 code splitting을 통해 페이지 로딩을 빠르게 함
- Client Side Routing에 최적화된 prefetching을 지원함
- 빌트인 CSS, Sass이 지원되며, 모든 CSS-in-JS 라이브러리를 지원함
- 빠른 재구동 개발 환경을 지원함
- serverless 함수를 이용해 API를 개발할 수 있게 API 라우터를 지원함
- 확장 가능함
등이 있다.
Reference
https://nextjs.org/learn/basics/create-nextjs-app