이 글은 이화여자대학교 2021-2학기 캡스톤디자인프로젝트A - 그로쓰7팀(이화BTS) 나정현의 기술 블로그 제출물입니다.
본 팀은 Data2Vis의 Encoder-Decoder 모델, Seq2Seq2 모델에 기반하여 “EDA를 위한 데이터 데이터 시각화 추천 시스템” 을 주제로 웹 서비스를 개발하고 있습니다. 해당 프로젝트에서 필자는 프론트엔드 개발 및 Node.js 백엔드 수정을 담당하였으며, 모델의 개략을 설명한 저번 포스팅에 이어 이번 포스팅에서는 모델을 웹 서비스에 올리고 그 중간 결과물을 만들기까지의 과정을 소개하고자 합니다.
GitHub 소스코드 : https://github.com/leahincom/erp-frontend
(※ 현재 비공개인 상태입니다.)
Project Overview
먼저, 해당 포스팅에 대한 이해를 돕기 위해 저번 포스팅과 같이 추천 시스템 과 ERP를 개발하게 된 이유에 대해 간략히 설명하면서 시작해보고자 한다.
Visualization Recommender System이란, 이름 그대로 전문가가 일일이 차트를 만들지 않아도 제공되는 차트 리스트 중에 가장 적합한 것을 고를 수 있도록 자동적으로 차트를 만들어 주는 추천 시스템이다. 본 팀은 정형화된 데이터셋을 이용하여 학습시킨 모델을 통해 시각화 타입과 디자인 초이스를 추천해주는 시스템을 설계하고, 이를 웹에 올려 Visualization 추천 시스템을 제공하는 ERP를 제작하고자 한다.
data를 활용하는 일이 급진적으로 증가하고 있고, 이에 따라 data specialist도 많아지고 있다. 이 트렌드에 맞게 굳이 플랏을 그리기까지의 모든 과정을 다 컨트롤하지 않아도 자동적으로 플랏을 추천해주는 서비스에 대한 요구도 증가하고 있다. 실제로 이에 가장 유명한 서비스는 Tableau 인데, 직접 사용해 본 결과 UI 도 복잡하고 UX도 좋지 못하다고 느꼈다. 하나의 윈도우에 너무 많은 정보가 한꺼번에 떠있는 느낌이었고, UX 플로우가 원활하지 못해 그리는 동안 어려움과 불편함을 느꼈다.
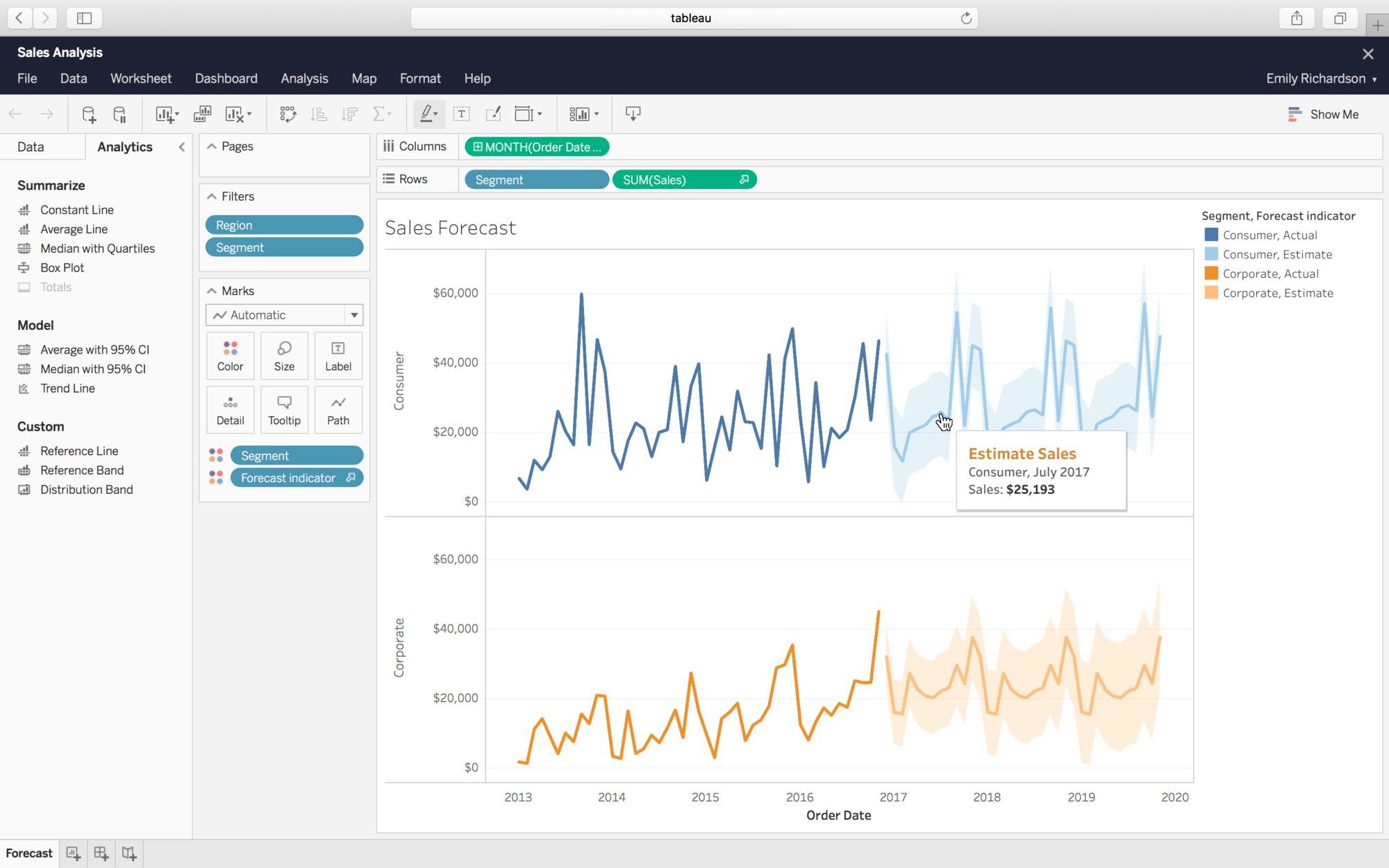
이를 보완하기 위해, 사용성이 뛰어난 노션 의 UI와 UX를 차용하여 위 서비스를 editor 형식을 이용한 사용자 중심 서비스로 탈바꿈하고자 한다. 본 팀의 서비스는 가장 중요한 분야 중 하나인 data 의 활용을 돕고 사용성을 증대시키고자 하며, 이를 통해 전문가가 데이터를 활용함에 있어서 중요한 부분에 집중할 수 있도록 돕고자 한다.
그렇다면, 본 팀의 프론트엔드와 백엔드에는 어떤 tech stack이 사용되었으며, 특히 프론트엔드에서 사용한 라이브러리는 어떤 것들이 있는지 살펴보고 간단한 튜토리얼을 통해 사용법을 알아보자.
WEB
웹에 사용한 테크 스택은 다음과 같다.
- React
- Styled-components
- Next.js
- Recoil
- Node.js
- Express.js
- Flask
- Tensorflow
- MongoDB
- Google Cloud Platform
1. Next.js를 채택한 이유
Server Side Rendering을 지원하던 기존 Multi Page Form 방식에서 모바일 사용자가 증가함에 따라 React, Angular, Vue 등 Client Side Rendering이 가능한 SPA가 등장하게 되었다. SPA는 1개의 페이지에서 수정되는 부분만 리렌더링하는 등 여러 동작이 이루어진다. 그렇다면 CSR이 아닌 SSR은 무엇이고, SSR 기반의 Next.js는 무엇일까?
SSR

서버에서 렌더링 작업을 수행하는 SSR은 사용자가 웹페이지에 접근할 때 서버에서 페이지에 대한 요청을 보내고, 서버에서 html, view 등의 리소스가 어떻게 보여질 지 해석되어 렌더링 후 사용자에게 반환하는 방식으로, 전체적인 프로세스는 다음과 같다.

여기서 첫번째 단계는 다음과 같이 이루어진다.
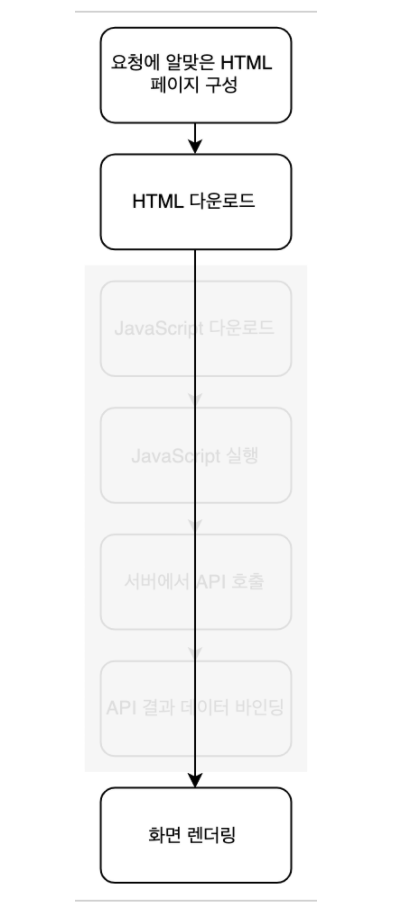
SSR이어도 Ajax 기능을 위해 클라이언트 렌더링 요소가 포함될 수 밖에 없다.
쉽게 설명하면, 페이지를 구성해서 그에 해당하는 html을 다운받아 화면에 렌더링하는 것으로, CSR에 비해 다운 받는 파일이 많지 않아 초기 로딩 속도가 빠르고, 사용자가 빨리 콘텐츠를 볼 수 있다. 근데 이 과정이 브라우저 👉 프론트 서버 👉 백엔드 서버 👉 데이터 베이스 를 거쳐 데이터를 받고 역순으로 브라우저까지 데이터를 가져와 그려야 하기 때문에, 페이지 이동/ 클릭 등으로 다른 요청이 생길 때마다 이 과정을 반복하면 변경되지 않은 부분도 계속해서 리렌더링되는 문제점이 있다. (서버 부하 등의 문제를 일으킬 수 있음)
Next.js란?
그래서 Next는 어떤 SSR과 CSR의 단점을 보완하는 걸까?
SSR은 불필요한 부분까지 리렌더링 되어 서버 부하가 발생할 수 있다는 점, CSR은 초기 로딩 속도가 느리고 SEO에 취약하다는 단점이 있다.
Next.js를 사용하여 첫페이지는 백엔드 서버에서 렌더링하여 빈 html이 아닌 데이터가 채워진 html을 받는다면 SEO 문제를 해결할 수 있다. 이후에는 CSR 방식에 따라 필요한 데이터만 받아 갱신한다면 서버 부하도 줄일 수 있다.
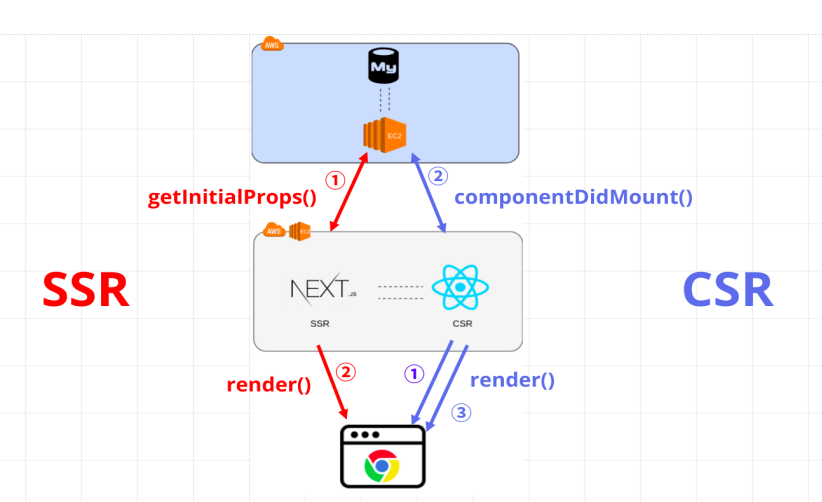
Next.js를 통해…
기존의 문제점인
- webpack과 같은 번들러를 통해 code를 번들하고 Babel과 같은 컴파일러로 변환해야 함
- code splitting과 같은 성능 최적화가 필요함
- 성능과 SEO를 위해 몇몇 페이지를 pre-render 해야할 수 있음
- React app과 데이터 스토어를 연동하기 위해 SSR 코드를 작성해야 할 수 있음
- 그냥, SSR과 CSR를 모두 사용하고 싶음
을 해결할 수 있다.
그러니까 Next.js의 특징은
- 페이지 기반의 라우팅 시스템 (CRA 시
pagefolder 생성) - 한 페이지 당 SSG와 SSR을 지원해 pre-rendering 가능
- 자동화된 code splitting을 통해 페이지 로딩을 빠르게 함
- Client Side Routing에 최적화된 prefetching을 지원함
- 빌트인 CSS, Sass이 지원되며, 모든 CSS-in-JS 라이브러리를 지원함
- 빠른 재구동 개발 환경을 지원함
- serverless 함수를 이용해 API를 개발할 수 있게 API 라우터를 지원함
- 확장 가능함
등이 있다.
Tutorial
- 먼저, CRA가 아닌
create-next-app을 이용해 프로젝트 폴더를 생성한다. 이 때, 필자는 typescript 를 이용하였기 때문에 해당 옵션--ts(또는--typescript)을 추가하였다.
1 | npx create-next-app erp-example --ts |
- 이후 기존 CRA는
npm start로 로컬호스트에서 라이브 서버를 실행했다면, next의 경우npm run dev를 통해 스크립트를 실행한다.
1 | npm run dev |
next는 page를
/pages폴더에서 관리하기 때문에, 해당 폴더 안의/pages/_app.tsx가 기존의index.js와 동일한 시작점으로 작용한다.이 때 주의해야 할 점은, 필자는 styled-components 를 사용하였기 때문에 추가적으로
/pages/_document.tsx를 생성해주어야 한다!여기서 해당 파일을 추가해주지 않으면, styled-components가 컴파일 후 생성하는 클래스명을 next가 인식하지 못해 렌더링 시 스타일 적용이 되지 않는다.
1
Warning : Props 'className' did not match ...
위의 warning이 그로 인한 이슈이다.
이후에는 CRA 이후와 동일하게
app.js대신index.tsx를 이용해 개발을 시작하면 된다!
2. 전역 상태 관리 Recoil
먼저 전역 상태 관리 라이브러리를 사용하기 전에, 어떤 값들을 상태로 관리해야 하는지, 이 중에서도 전역 상태로 사용해야 할 값들은 어떤 것들인지 추리는 것이 중요하다. 상태를 많이 사용하다보면 dependency가 과도하게 생성되어 사소한 값을 변경할 때도 불필요한 렌더링과 의도치 않은 값 변경 등 코드의 복잡도가 매우 높아질 수 있다. 따라서 hook을 이용한 상태 관리는 최소화하는 것이 좋기 때문에, 다음과 같은 사항을 고려한 후 상태값을 생성하는 것이 중요하다.
- 꼭 전역 상태로 관리해야 할까?
- 용도에 따라 상태값 분리
- 데이터 별로 동기/ 비동기 생각하기
- 데이터가 변경되는 시점, 영향을 주고받는 의존성 파악하기
필자는 전역 상태 관리를 위해 recoil.js 라이브러리를 사용하였는데, 이를 선택한 이유는
- React를 개발한 Facebook이 내놓은 라이브러리
- 따라서 React에 가장 적합한 상태 관리 기능을 제공할 것이라 생각
- 러닝 커브가 낮아 배우기 쉽고 사용이 편리
등등이 있다.
Context API나 Redux, MobX보다 훨씬 간편하게 사용이 가능하고 필요한 기능은 모두 포함되었기 때문에 Recoil이면 충분하다고 생각했다.
그렇다면 Recoil은 무엇이고 어떤 기능을 제공할까?
왜 Recoil을 사용해야 할까?
데이터 플로우를 잘 관리해서 의존성을 갖는 상태를 잘 관리하는 것
State changes flow from the roots of this graph (which we call atoms) through pure functions (which we call selectors) and into components.
기본 개념
- RecoilRoot
1 | import React from 'react'; |
- define in a root component
- Atoms
1 | const fontSizeState = atom({ |
- units of state
- updateable and subscribable: when an atom is updated, each subscribed component is re-rendered with the new value
- Components that read the value of an atom are implicitly subscribed to that atom
- unique key: two atoms to have the same key, so make sure they’re globally unique
useRecoilState
- read and write an atom from a component
- just like React’s
useStatewhich can be shared between components
useRecoilValue
- To read the contents of this atom, we can use the
useRecoilValue()hook in ourTodoListcomponent
- To read the contents of this atom, we can use the
useSetRecoilState
- We can use the
useSetRecoilState()hook to get a setter function in ourTodoItemCreatorcomponent
- We can use the
- Selector
1 | const fontSizeLabelState = selector({ |
- pure function that accepts atoms or other selectors as input → upstream atoms or selectors are updated, the selector function will be re-evaluated
- Components can subscribe to selectors just like atoms, and will then be re-rendered when the selectors change
- calculate derived data that is based on state
- derived state: transformation of state = the output of passing state to a pure function that modifies the given state
- minimal set of state is stored in atoms, while everything else is efficiently computed as a function of that minimal state
- selectors keep track of what components need them and what state they depend on
get
getproperty is the function that is to be computed- access the value of atoms and other selectors
- accesses another atom or selector, a dependency relationship is created
useRecoilValue
- takes an atom or selector as an argument and returns the corresponding value
1 | const [fontSize, setFontSize] = useRecoilState(fontSizeState); |
그렇다면, 본 프로젝트에서 중점적으로 recoil을 이용해 전역 상태 관리를 하고자 한 이유인 비동기 데이터 쿼리 에 대해 알아보고, 간단한 예시를 통해 작동 원리를 파악해보자.
비동기 데이터 쿼리
- these are just selectors, other selectors can also depend on them to further transform the data
- the functions in the graph can also be asynchronous
- asynchronous functions in synchronous React component render functions
- mix synchronous and asynchronous functions in your data-flow graph of selectors
- return a Promise to a value instead of the value itself from a selector
getcallback, the interface remains exactly the same - one way to incorporate asynchronous data into the Recoil data-flow graph
- a given set of inputs they should always produce the same results (because selector evaluations may be cached, restarted, or executed multiple times)
- Synchronous
1 | const currentUserIDState = atom({ |
- Asynchronous
1 | const currentUserNameQuery = selector({ |
Tutorial
먼저 프로젝트를 생성한다.
1
npx create-react-app my-app
recoil을 설치한다.
1
npm install recoil
recoil을 이용하기 위해서는 state가 필요한 컴포넌트의 부모 트리 혹은 최상단에
RecoilRoot를 넣어야 한다. 기존의 Context API에서 Context Provider를 부모 트리에 넣고 안에 Consumer을 정의하는 것과 같은 원리이다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import React from 'react';
import {
RecoilRoot,
atom,
selector,
useRecoilState,
useRecoilValue,
} from 'recoil';
function App() {
return (
<RecoilRoot>
<CharacterCounter />
</RecoilRoot>
);
}이후 state 정의를 위한
atom과selector의 생성은 위의 기본 개념 파트를 참고하면 된다 :)
3. 사용한 라이브러리
React는 커뮤니티가 활성화되어 있어 사용할 수 있는 라이브러리가 많고, 그에 따라 효과적, 효율적으로 기능을 추가할 수 있다. 특히 처음부터 모든 기능을 직접 구현하다 보면 각 기능에서 발생 가능한 이슈를 핸들링하느라 수고가 늘어나는데, 라이브러리는 각 피쳐에 집중적으로 개발이 되었기 때문에 발생 가능한 이슈를 자체적으로 핸들링하고, 유지 보수가 잘 되고 있는 라이브러리는 이를 계속 체크업하기 때문에 더더욱 유용하게 사용할 수 있다.
하지만 개발하는 서비스에 맞게 커스터마이징을 힘든 경우가 있기 때문에, 라이브러리를 선택할 때는 여러 요건을 고려하여야 한다. 이에 가장 기본적인 요건은
- 사용자 수 (활성화된 커뮤니티)
- 꾸준한 유지 보수
- 다양한 커스터마이징 기능?
등등이 있다.
해당 프로젝트에서는 editor 형식으로 대시보드를 구현하였기 때문에 다양한 라이브러리를 사용해 효과적으로 개발하고자 노력하였으며, 모델을 올리는 경우에도 vega 측에서 제공하는 리액트 용 vega-lite 라이브러리를 이용하여 사용하는 모델의 기능을 최대한 제공할 수 있도록 하였다. 본 프로젝트의 프론트엔드 package.json 은 다음과 같다.
1 | "@fortawesome/fontawesome-svg-core": "^1.2.36", |
ERP의 #FE
그래서, 현 ERP의 프론트엔드는 어느 시점까지 개발되었을까?
현재 사용자가 정형화된 csv 형식의 데이터를 업로드하면 학습된 추천 시스템 모델을 통해 여러 추천 플랏이 반환되며, 사용자는 각 플랏을 선택하여 자세하게 이를 확인할 수 있다.

이는 데이터의 spec 과 data 부분을 분리하여 VegaLite 라이브러리 컴포넌트를 이용하여 구현하였다. 각 플랏 당 해당 플랏을 저장하거나, 데이터 코드를 볼 수 있는 기능 등이 포함된 옵션을 제공하므로 플랏 오른쪽 상단에 위치한 옵션 버튼을 선택하면 다양한 기능을 확인해볼 수 있다.
또한, 에디터 형식의 대시보드를 구현하여 기본적인 텍스트와 이미지 업로드를 통한 보고서 작성이 가능하다. 사용자가 로드한 데이터 별로 플랏을 저장하여 차후 데이터 요약 보고서 생성 시 로드한 데이터를 선택해 저장한 플랏을 불러오고 에디터에 원하는 플랏을 업로드할 수 있다.

Conclusion
본 팀은 최종 발표까지 남은 기간 +a의 기간 동안 QA 진행 및 유저 피드백을 반영하여 기능을 수정 및 보완하고, 배포와 리팩토링을 진행할 예정이다. 더하여 프리미엄 버전으로 사용자가 실제로 데이터 요약 보고서를 사용함에 있어서 더욱 정교하게 추천 시스템을 활용하여 효율적이고 능률적으로 서비스를 이용할 수 있도록 여러 기능을 덧붙여 볼 예정이다.
결론적으로 목표하는 바는 효과적인 EDA를 위한 Customizing Recommended Data Visualization Plots 서비스를 제공하고 유지, 보수 관리를 꾸준히 이어나가는 것이다.