여기서, onmouseup과 onclick의 차이 는 무엇일까?
마우스를 버튼에서 누른 상태에서 버튼의 영역을 벗어나서 버튼을 놓았을때 차이가 존재한다.
onClick이벤트 : 이벤트 함수가 실행이 안 됨, 왼쪽 클릭에 한하여 이벤트 발생onMouseUp이벤트 : 이벤트 함수가 실행이 됨, 모든 클릭 적용
여기서, onmouseup과 onclick의 차이 는 무엇일까?
마우스를 버튼에서 누른 상태에서 버튼의 영역을 벗어나서 버튼을 놓았을때 차이가 존재한다.
onClick 이벤트 : 이벤트 함수가 실행이 안 됨, 왼쪽 클릭에 한하여 이벤트 발생
onMouseUp 이벤트 : 이벤트 함수가 실행이 됨, 모든 클릭 적용
다소 복잡한 코드로 보일 수 있으나, 사용한 라이브러리의 구조를 뜯어보고 조합해서 코드를 읽으면 이해할 수 있다 🤗
최초 렌더링 시 마운트 되어야 하는 조건은 다음 2가지 경우에 따라 다르다.
1의 경우 전달받은 인자에 알맞게 내용을 입력해서 placeholder를 설정하고,
1 | if (!hasPlaceholder) { |
2의 경우 기존의 state가 존재하는 경우이므로 거기에 전달받은 props의 내용을 덧붙여 렌더링한다.
1 | this.addPlaceholder({ |
최초의 렌더링 이후, 컴포넌트가 업데이트 될 때 (state/ props/ 부모 컴포넌트가 업데이트 됨에 따라) 실행되는 코드이다.
여기서 업데이트는 잦게 발생하고 보통 블록의 업데이트가 연관되는데, 다음과 같은 조건을 고려하여 블록을 업데이트 시킨다. 입력 할 때마다 업데이트하는 것이 아니라, 입력이 멈추었을 때 블록을 대상으로 업데이트 시켜야 렌더링 이슈가 발생하지 않는다.
1 | if (((stoppedTyping && htmlChanged) || tagChanged || imageChanged) && hasNoPlaceholder) { |
컴포넌트가 업데이트 될 때마다 컴포넌트 리렌더링 직전 실행되는 코드로, 어떤 경우든 상관없이 업데이트 될 때마다 실행되어야 하는 코드를 넣는다.
현재 openActionMenu 에 addEventListener 로 이벤트 핸들러가 세팅되어 있는 상태라고 가정할 때, 아래와 같은 코드가 있다고 가정해보자.
1 | componentWillUnmount() { |
위 코드는 Component가 Will Unmount 할 때, remove Event Listener를 수행하게 될 것이다.
ComponentWillUnmount 는 useEffect 에서 return문이랑 동일한데, 하는 역할은 ComponentDidUpdate 직전, 즉, 리렌더링이 일어나기 직전 수행하고 다음 작업을 진행하는 것이다.
이와 같은 작업을 설정한 이유는, 여기서 closeActionMenu 는 action menu가 open 된 상태에서 어디를 클릭하든 menu가 close 되어야 하기 때문이다. 조건 없이 무조건 컴포넌트 상태에 변동이 있을 때 액션 메뉴가 닫혀야 하기 때문에 액션 메뉴를 열게 한 EventHandler를 제거해야 한다. 따라서 click 시 closeActionMenu가 실행되어야 하는 것이다.
user가 / 커맨드를 keydown 했을 때 openSelectMenuHandler() 하는 것이 맞아보이지만, 실제로 keyup 을 했을 때 해당 메소드를 실행해야 한다. 사용자가 / 커맨드 입력을 완료해야 액션 메뉴가 떠야 하는데, 여기서 완료란 키 press가 떼어졌을 때 이기 때문이다. 따라서 handleKeyUp 에는 다음과 같은 코드를 작성한다.
1 | handleKeyUp(e: any) { |
그렇다면 onkeydown 에는 어떤 작업이 필요할까?
일단 사용자가 keydown하는 key에는 크게
command key (/): tag를 담은 tagSelectorMenu 오픈
/ 입력 시 현재까지 입력 중이던 this.state.html 의 내용을 백업해두기 위해 htmlBackup 에 저장한다.
Backspace key
단일: 새로운 블록
html 내용이 없는 상태에서 backspace를 눌렀다면 블록을 지우는 것이다.
Enter key
타이핑을 위해: html (혹은 htmlBackup) 내용 입력
그리고 위 모든 경우에 관계없이 누른 키를 previousKey 로 등록하여 다른 키 이벤트 발생 시 조합해서 고려해야 한다. (Shift + Enter 처럼)
1 | handleKeyDown(e: any) { |
actionMenu 는 아래와 같다.

블록 관점에서 mouse 이벤트가 핸들링 되어야 하는 경우는 ContentEditable 의 current가 존재하는 (focus가 된, 수정 중인) 대상이 있을 때에 한해서
1의 경우, ContentEditable 의 text를 range 잡아 (드래그해서 단어문장문단 택) 클릭한 경우이다! 이 경우 actionMenu가 오픈되어야 하는 위치는 텍스트 range의 가운데 위이다. 해당 위치 계산을 위해 'TEXT_SELECTION' 을 키로 전달하여 actionMenu 오픈 시 위치가 계산되도록 한다.
이 경우에는 text가 range에 잡혀 selection에 추가한 range의 start와 end가 다르다. (블록의 text 시작 위치 === start, 끝 위치 === end) 이게 같은 경우에는 text 입력에 따른 actionMenu가 실행되는 경우가 아니므로 처리하지 않는다.
1 | handleMouseUp() { |
2의 경우 블록 오른쪽에 위치한, drag-n-drop 표시를 위한 아이콘을 onclick 한 상태이므로, 'DRAG_HANDLE_CLICK' 를 키로 전달한다. 이 경우 아이콘 바로 왼쪽에 actionMenu가 오픈되어야 한다.
1 | handleDragHandleClick(e: any) { |
actionMenu가 open된 후 발생하는 클릭 이벤트를 핸들링 하기 위해서는, range의 변경이 완료되었다고 판단하는 시간을 0.1초로 가정하고 이벤트 핸들러로 하여금 작동하도록 한다. 이러지 않으면, 사용자가 텍스트를 드래그하여 Range를 정하는 것과 맞물려 작동해 에러가 발생할 수 있으므로 불편을 초래할 수 있다.
1 | openActionMenu(parent: any, trigger: string) { |
또한 actionMenu가 닫힌 후에는 removeEventListener 를 통해 click에 대한 이벤트를 제거해야 이벤트 버블링을 방지할 수 있다.
tagSelectorMenu는 / 입력하는 html tag들을 담은 메뉴 아이템을 의미한다.
메뉴에서 tag를 select 했을 때 이벤트를 핸들링하는 handleTagSelection 을 살펴보자.
먼저, 이 핸들러는 전달된 tag 인자에 따라 추가된 블록의 html tag 타입을 설정해야 하는데, Enter 키 등으로 블록을 생성한 것이 아니라 페이지가 새로 생성된 최초의 상태에 default로 하나의 블록을 생성해 놓아야 한다.
여기서 사용자가 커맨드로 입력한 tag에 따라 기존 allowedTags 에서 sorting을 해야하기 때문에 match-sorter 라이브러리를 사용했다. 이 라이브러리에서 matchSorter 를 사용할 때 전달하는 인자 중 3번째 option 객체에 keys 를 넣어 전달할 수 있는데, 얘가 바로 default의 경우를 핸들링하는 키이다. 우리는 최초의 블록
1 | { |
을 렌더링 하기 위해 key로써 'tag' 를 핸들러의 인자로 전달한다.
이 외에, tag selector menu에서 클릭 이벤트 없이 typing할 경우 사용자가 내용을 입력하는 것이므로 기존에 입력 중이던 내용을 백업해놓는 htmlBackup 이 존재할 것이기 때문에 그에 이어서 내용을 덧붙인다.
최종적으로 위 모든 경우가 아닌 것은 메뉴 중 태그를 선택한 경우이므로 블록의 태그를 설정하고 메뉴를 닫으면 된다.
1 | handleTagSelection(tag: string) { |
그리고 이 메뉴를 여닫는 메소드는 actionMenu의 경우와 비슷하다. (여기서는 setTimeout 을 설정하지 않아도 된다. range의 변화와 같이 짧은 시간 내 변화가 많이 축적되는 이벤트가 발생하는 것이 아니기 때문이다. 클릭 이벤트 한 번일 뿐!)
1 | openTagSelectorMenu(trigger?: string) { |
setCaretToEnd: current 블록이 변경될 때 cursor (caret) 의 위치는 해당 블록 내 텍스트의 end 여야 한다.
1 | range.collapse(false) // false === end, true === start |
getSelection: 블록 내 텍스트를 드래그하여 텍스트 range를 생성(형성)할 때
getCaretCoordinates: caret을 내포하는 블록(=== coordinates)의 위치를 계산하기 위해
텍스트의 범위를 드래그/ 선택함에 따라 생기는 Range와 이를 가능하게 하는 Selection 객체를 이용해 커서 혹은 블록의 위치를 특정할 수 있다.
이 과정 없이 focus 를 취하면 커서의 위치는 텍스트의 처음으로 설정된다.
document는 window의 프로퍼티 (window.document는 document에 대한 레퍼런스를 리턴한다) 이다.
1 | // Fragment of a document that can contain nodes and parts of text nodes |
1 | // Selection object representing the range of text selected by the user or the current position of the caret |
1 | // sets the Range to the contents of a Node |
1 | // collapse the Range to one of its boundary points |
1 | // set the anchorNode & focusNode to null |
이 글은 이화여자대학교 2021-2학기 캡스톤디자인프로젝트A - 그로쓰7팀(이화BTS) 나정현의 기술 블로그 제출물입니다.
본 팀은 Data2Vis의 Encoder-Decoder 모델, Seq2Seq2 모델에 기반하여 “EDA를 위한 데이터 데이터 시각화 추천 시스템” 을 주제로 웹 서비스를 개발하고 있습니다. 해당 프로젝트에서 필자는 프론트엔드 개발 및 Node.js 백엔드 수정을 담당하였으며, 모델의 개략을 설명한 저번 포스팅에 이어 이번 포스팅에서는 모델을 웹 서비스에 올리고 그 중간 결과물을 만들기까지의 과정을 소개하고자 합니다.
GitHub 소스코드 : https://github.com/leahincom/erp-frontend
(※ 현재 비공개인 상태입니다.)
먼저, 해당 포스팅에 대한 이해를 돕기 위해 저번 포스팅과 같이 추천 시스템 과 ERP를 개발하게 된 이유에 대해 간략히 설명하면서 시작해보고자 한다.
Visualization Recommender System이란, 이름 그대로 전문가가 일일이 차트를 만들지 않아도 제공되는 차트 리스트 중에 가장 적합한 것을 고를 수 있도록 자동적으로 차트를 만들어 주는 추천 시스템이다. 본 팀은 정형화된 데이터셋을 이용하여 학습시킨 모델을 통해 시각화 타입과 디자인 초이스를 추천해주는 시스템을 설계하고, 이를 웹에 올려 Visualization 추천 시스템을 제공하는 ERP를 제작하고자 한다.
data를 활용하는 일이 급진적으로 증가하고 있고, 이에 따라 data specialist도 많아지고 있다. 이 트렌드에 맞게 굳이 플랏을 그리기까지의 모든 과정을 다 컨트롤하지 않아도 자동적으로 플랏을 추천해주는 서비스에 대한 요구도 증가하고 있다. 실제로 이에 가장 유명한 서비스는 Tableau 인데, 직접 사용해 본 결과 UI 도 복잡하고 UX도 좋지 못하다고 느꼈다. 하나의 윈도우에 너무 많은 정보가 한꺼번에 떠있는 느낌이었고, UX 플로우가 원활하지 못해 그리는 동안 어려움과 불편함을 느꼈다.
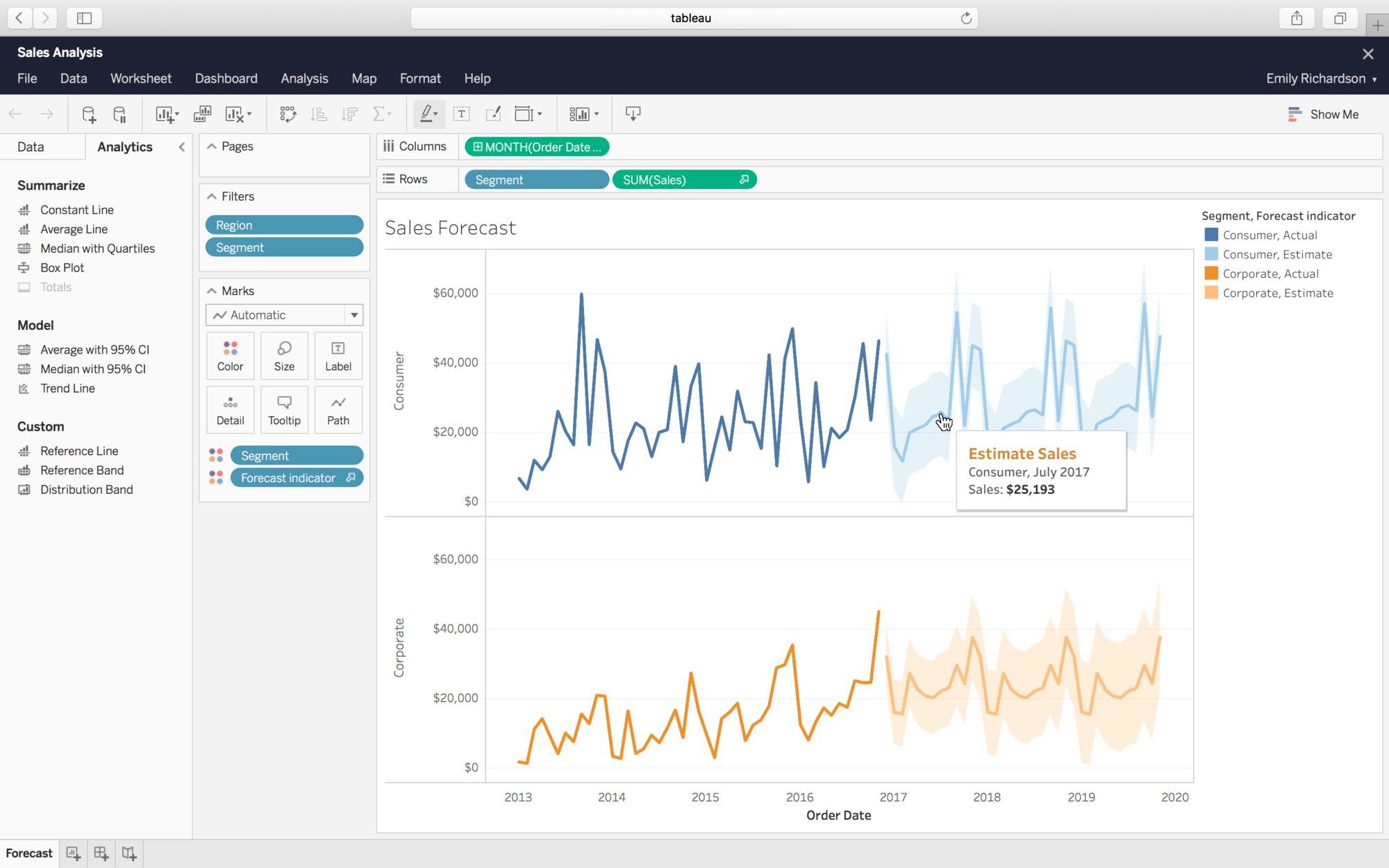
이를 보완하기 위해, 사용성이 뛰어난 노션 의 UI와 UX를 차용하여 위 서비스를 editor 형식을 이용한 사용자 중심 서비스로 탈바꿈하고자 한다. 본 팀의 서비스는 가장 중요한 분야 중 하나인 data 의 활용을 돕고 사용성을 증대시키고자 하며, 이를 통해 전문가가 데이터를 활용함에 있어서 중요한 부분에 집중할 수 있도록 돕고자 한다.
그렇다면, 본 팀의 프론트엔드와 백엔드에는 어떤 tech stack이 사용되었으며, 특히 프론트엔드에서 사용한 라이브러리는 어떤 것들이 있는지 살펴보고 간단한 튜토리얼을 통해 사용법을 알아보자.
웹에 사용한 테크 스택은 다음과 같다.
Server Side Rendering을 지원하던 기존 Multi Page Form 방식에서 모바일 사용자가 증가함에 따라 React, Angular, Vue 등 Client Side Rendering이 가능한 SPA가 등장하게 되었다. SPA는 1개의 페이지에서 수정되는 부분만 리렌더링하는 등 여러 동작이 이루어진다. 그렇다면 CSR이 아닌 SSR은 무엇이고, SSR 기반의 Next.js는 무엇일까?

서버에서 렌더링 작업을 수행하는 SSR은 사용자가 웹페이지에 접근할 때 서버에서 페이지에 대한 요청을 보내고, 서버에서 html, view 등의 리소스가 어떻게 보여질 지 해석되어 렌더링 후 사용자에게 반환하는 방식으로, 전체적인 프로세스는 다음과 같다.

여기서 첫번째 단계는 다음과 같이 이루어진다.
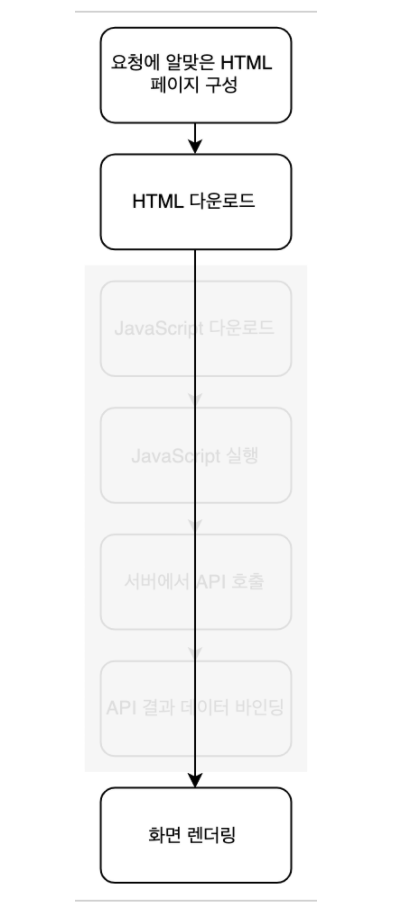
SSR이어도 Ajax 기능을 위해 클라이언트 렌더링 요소가 포함될 수 밖에 없다.
쉽게 설명하면, 페이지를 구성해서 그에 해당하는 html을 다운받아 화면에 렌더링하는 것으로, CSR에 비해 다운 받는 파일이 많지 않아 초기 로딩 속도가 빠르고, 사용자가 빨리 콘텐츠를 볼 수 있다. 근데 이 과정이 브라우저 👉 프론트 서버 👉 백엔드 서버 👉 데이터 베이스 를 거쳐 데이터를 받고 역순으로 브라우저까지 데이터를 가져와 그려야 하기 때문에, 페이지 이동/ 클릭 등으로 다른 요청이 생길 때마다 이 과정을 반복하면 변경되지 않은 부분도 계속해서 리렌더링되는 문제점이 있다. (서버 부하 등의 문제를 일으킬 수 있음)
그래서 Next는 어떤 SSR과 CSR의 단점을 보완하는 걸까?
SSR은 불필요한 부분까지 리렌더링 되어 서버 부하가 발생할 수 있다는 점, CSR은 초기 로딩 속도가 느리고 SEO에 취약하다는 단점이 있다.
Next.js를 사용하여 첫페이지는 백엔드 서버에서 렌더링하여 빈 html이 아닌 데이터가 채워진 html을 받는다면 SEO 문제를 해결할 수 있다. 이후에는 CSR 방식에 따라 필요한 데이터만 받아 갱신한다면 서버 부하도 줄일 수 있다.
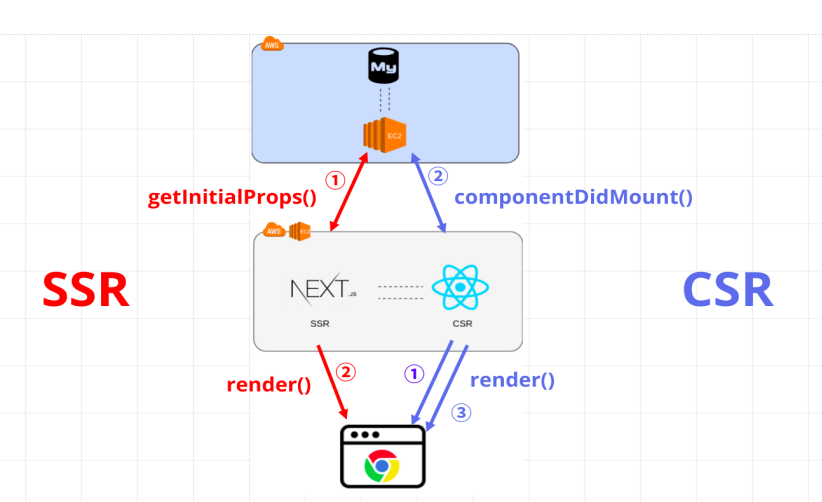
기존의 문제점인
을 해결할 수 있다.
그러니까 Next.js의 특징은
page folder 생성)등이 있다.
create-next-app 을 이용해 프로젝트 폴더를 생성한다. 이 때, 필자는 typescript 를 이용하였기 때문에 해당 옵션 --ts (또는 --typescript)을 추가하였다.1 | npx create-next-app erp-example --ts |
npm start 로 로컬호스트에서 라이브 서버를 실행했다면, next의 경우 npm run dev 를 통해 스크립트를 실행한다.1 | npm run dev |
next는 page를 /pages 폴더에서 관리하기 때문에, 해당 폴더 안의 /pages/_app.tsx 가 기존의 index.js 와 동일한 시작점으로 작용한다.
이 때 주의해야 할 점은, 필자는 styled-components 를 사용하였기 때문에 추가적으로 /pages/_document.tsx 를 생성해주어야 한다!
여기서 해당 파일을 추가해주지 않으면, styled-components가 컴파일 후 생성하는 클래스명을 next가 인식하지 못해 렌더링 시 스타일 적용이 되지 않는다.
위의 warning이 그로 인한 이슈이다.
이후에는 CRA 이후와 동일하게 app.js 대신 index.tsx 를 이용해 개발을 시작하면 된다!
먼저 전역 상태 관리 라이브러리를 사용하기 전에, 어떤 값들을 상태로 관리해야 하는지, 이 중에서도 전역 상태로 사용해야 할 값들은 어떤 것들인지 추리는 것이 중요하다. 상태를 많이 사용하다보면 dependency가 과도하게 생성되어 사소한 값을 변경할 때도 불필요한 렌더링과 의도치 않은 값 변경 등 코드의 복잡도가 매우 높아질 수 있다. 따라서 hook을 이용한 상태 관리는 최소화하는 것이 좋기 때문에, 다음과 같은 사항을 고려한 후 상태값을 생성하는 것이 중요하다.
필자는 전역 상태 관리를 위해 recoil.js 라이브러리를 사용하였는데, 이를 선택한 이유는
등등이 있다.
Context API나 Redux, MobX보다 훨씬 간편하게 사용이 가능하고 필요한 기능은 모두 포함되었기 때문에 Recoil이면 충분하다고 생각했다.
그렇다면 Recoil은 무엇이고 어떤 기능을 제공할까?
데이터 플로우를 잘 관리해서 의존성을 갖는 상태를 잘 관리하는 것
State changes flow from the roots of this graph (which we call atoms) through pure functions (which we call selectors) and into components.
1 | import React from 'react'; |
1 | const fontSizeState = atom({ |
useRecoilState
useState which can be shared between componentsuseRecoilValue
useRecoilValue() hook in our TodoList componentuseSetRecoilState
useSetRecoilState() hook to get a setter function in our TodoItemCreator component1 | const fontSizeLabelState = selector({ |
get
get property is the function that is to be computeduseRecoilValue
1 | const [fontSize, setFontSize] = useRecoilState(fontSizeState); |
그렇다면, 본 프로젝트에서 중점적으로 recoil을 이용해 전역 상태 관리를 하고자 한 이유인 비동기 데이터 쿼리 에 대해 알아보고, 간단한 예시를 통해 작동 원리를 파악해보자.
get callback, the interface remains exactly the same1 | const currentUserIDState = atom({ |
1 | const currentUserNameQuery = selector({ |
먼저 프로젝트를 생성한다.
1 | npx create-react-app my-app |
recoil을 설치한다.
1 | npm install recoil |
recoil을 이용하기 위해서는 state가 필요한 컴포넌트의 부모 트리 혹은 최상단에 RecoilRoot 를 넣어야 한다. 기존의 Context API에서 Context Provider를 부모 트리에 넣고 안에 Consumer을 정의하는 것과 같은 원리이다.
1 | import React from 'react'; |
이후 state 정의를 위한 atom 과 selector 의 생성은 위의 기본 개념 파트를 참고하면 된다 :)
React는 커뮤니티가 활성화되어 있어 사용할 수 있는 라이브러리가 많고, 그에 따라 효과적, 효율적으로 기능을 추가할 수 있다. 특히 처음부터 모든 기능을 직접 구현하다 보면 각 기능에서 발생 가능한 이슈를 핸들링하느라 수고가 늘어나는데, 라이브러리는 각 피쳐에 집중적으로 개발이 되었기 때문에 발생 가능한 이슈를 자체적으로 핸들링하고, 유지 보수가 잘 되고 있는 라이브러리는 이를 계속 체크업하기 때문에 더더욱 유용하게 사용할 수 있다.
하지만 개발하는 서비스에 맞게 커스터마이징을 힘든 경우가 있기 때문에, 라이브러리를 선택할 때는 여러 요건을 고려하여야 한다. 이에 가장 기본적인 요건은
등등이 있다.
해당 프로젝트에서는 editor 형식으로 대시보드를 구현하였기 때문에 다양한 라이브러리를 사용해 효과적으로 개발하고자 노력하였으며, 모델을 올리는 경우에도 vega 측에서 제공하는 리액트 용 vega-lite 라이브러리를 이용하여 사용하는 모델의 기능을 최대한 제공할 수 있도록 하였다. 본 프로젝트의 프론트엔드 package.json 은 다음과 같다.
1 | "@fortawesome/fontawesome-svg-core": "^1.2.36", |
그래서, 현 ERP의 프론트엔드는 어느 시점까지 개발되었을까?
현재 사용자가 정형화된 csv 형식의 데이터를 업로드하면 학습된 추천 시스템 모델을 통해 여러 추천 플랏이 반환되며, 사용자는 각 플랏을 선택하여 자세하게 이를 확인할 수 있다.

이는 데이터의 spec 과 data 부분을 분리하여 VegaLite 라이브러리 컴포넌트를 이용하여 구현하였다. 각 플랏 당 해당 플랏을 저장하거나, 데이터 코드를 볼 수 있는 기능 등이 포함된 옵션을 제공하므로 플랏 오른쪽 상단에 위치한 옵션 버튼을 선택하면 다양한 기능을 확인해볼 수 있다.
또한, 에디터 형식의 대시보드를 구현하여 기본적인 텍스트와 이미지 업로드를 통한 보고서 작성이 가능하다. 사용자가 로드한 데이터 별로 플랏을 저장하여 차후 데이터 요약 보고서 생성 시 로드한 데이터를 선택해 저장한 플랏을 불러오고 에디터에 원하는 플랏을 업로드할 수 있다.

본 팀은 최종 발표까지 남은 기간 +a의 기간 동안 QA 진행 및 유저 피드백을 반영하여 기능을 수정 및 보완하고, 배포와 리팩토링을 진행할 예정이다. 더하여 프리미엄 버전으로 사용자가 실제로 데이터 요약 보고서를 사용함에 있어서 더욱 정교하게 추천 시스템을 활용하여 효율적이고 능률적으로 서비스를 이용할 수 있도록 여러 기능을 덧붙여 볼 예정이다.
결론적으로 목표하는 바는 효과적인 EDA를 위한 Customizing Recommended Data Visualization Plots 서비스를 제공하고 유지, 보수 관리를 꾸준히 이어나가는 것이다.
1 | class CustomOption extends Component { |
class 컴포넌트에서 함수형 컴포넌트로 리팩토링
👇
addStar 을 설정하고, 반환하는 컴포넌트에 이를 onClick 의 속성으로 설정한다.1 | const CustomOption = ({ |
onChange 를 받기 위해 React Component를 extend한 인터페이스를 설정한다.1 | interface CustomOptionProps extends ComponentProps<React.ElementType> { |
1 | toolbarCustomButtons={[ |
1 | click-events-have-key-events |
1 | aria hidden |
createRef : 클래스형 컴포넌트에서 사용
useRef : 함수형 컴포넌트에서 사용
React 컴포넌트는 기본적으로 내부 상태(state)가 변할 때 마다 다시 랜더링(rendering)이 된다. 컴포넌트 함수가 다시 호출이 된다는 것은 함수 내부의 변수들이 모두 초기화가 되고 함수의 모든 로직이 다시 실행된다는 것을 의미한다.
다시 렌더링 되어도 동일한 참조값을 유지하려면?
리렌더링 시 함수 내부의 변수들이 기존에 저장하고 있는 값들을 잃어버리고 초기화되는데, 간혹 다시 랜더링이 되더라도 기존에 참조하고 있던 컴포넌트 함수 내의 값이 그대로 보존되야 하는 경우가 있다.
useRef 는 current 속성을 가지고 있는 객체를 반환하는데, 인자로 넘어온 초기값을 current 속성에 할당한다. 이 current 속성은 값을 변경해도 상태를 변경할 때처럼 React 컴포넌트가 다시 랜더링되지 않는다. React 컴포넌트가 다시 랜더링될 때도 마찬가지로 이 current 속성의 값이 유실되지 않는다.
DOM 노드나 React 엘리먼트에 직접 접근하기 위해서
React의 ref prop은 HTML 엘리먼트의 레퍼런스를 변수에 저장하기 위해서 사용한다.
예를 들어, 다음과 같이 <input> 엘리먼트에 ref prop으로 inputRef라는 변수를 넘기게 되면, 우리는 이 inputRef 객체의 current 속성을 통해서 <input> 엘리먼트에 접근할 수 있고, DOM API를 이용하여 제어할 수 있습니다.
1 | <input ref={inputRef} /> |
useRef에 ref element들을 할당해야 하므로 배열로 초기값 선언
객체를 할당해도 된다.
1 | const refs = useRef([]); |
위와 같이 빈 배열(객체)을 전달하면, 여러개의 DOM element를 refs에 담을 수 있다.
1 | <div> |
할당한 객체에 맞게 접근하기 위해, ref.current에서 배열의 index나 객체의 property를 이용하여 접근한다.
1 | refs.current[currentInput] |
1 | function CustomTextInput(props) { |
useRef를 정의하는 곳과 사용하는 곳이 한 곳에 존재하면, react hooks의 특성상 동적으로 그 개수를 늘려가며 선언할 수 없다. 반면 방법1과 방법2에서는 동적으로 늘어나도 동일한 매커니즘으로 동작할 수 있다.
1 | function CustomTextInput({focused}) { |
1 | function Form({focused}) { |
useState hook을 이용해서 구현
react-draft-wysiwyg/src/Editor/index.jsthis.props.hashtag : Wysiwyg 컴포넌트에 전달하는 Props 중 hashtag 속성에 객체 전달1 | getCompositeDecorator = toolbar => { |
react-draft-wysiwyg/src/decorators/HashTag/index.jshashCharacter: trigger로 작용separator: endpoint로 작용1 | constructor(config) { |
클라이언트에서 커맨드 라인이나 소스코드로 손 쉽게 웹 브라우저 처럼 활동할 수 있도록 해주는 기술 (커맨드라인 Tool 혹은 라이브러리)
서버와 통신할 수 있는 커맨드 명령어 툴
무료 오픈소스
다양한 지원 프로토콜들
DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, Telnet, TFTP
SSL 인증 방식 가능
url을 가지고 할 수 있는 것들은 다할 수 있다.
1 | curl [-option] url |
.env 파일을 만든다..env 파일에 설정하고 싶은 변수를 작성한다..env 파일의 변수를 사용하려면 변수명 앞에 prefix로 REACT_APP_ 을 붙여야 한다는 점!1 | REACT_APP_API_KEY = "blabla" |
1 | const API_KEY = process.env.REACT_APP_API_KEY; |
.env 파일을 .gitignore 에 추가해준다.useEffect()의 return문
componentDidMount 직전 useEffect의 return문 출력하고, 이후 useEffect 내용이 실행된다.
그 이후 리렌더 때 return문을 실행한다.
useEffect 함수의 return === 일반적인 class기반 컴포넌트의 Lifecycle에서 componentWillUnmount
1 | const App = () => { |
dependency array
componentDidMount as in, it only runs once.componentDidMount and componentDidUpdate, as in it runs first on mount and then on every re-render.[variable1]) will only execute the code inside your useEffect hook ONCE on mount, as well as whenever that particular variable (eg. variable1) changes.